布隆过滤器
1. 什么是布隆过滤器
布隆过滤器(Bloom Filter)是一个空间效率很高的数据结构,用于判断一个元素是否在一个集合中。布隆过滤器的核心思想是利用位数组和一系列随机映射函数(哈希函数)来快速判断某个元素是否存在于集合中,但存在一定的误判率。
2. 参数
布隆过滤器的参数主要包括以下几个方面:
(1)预插入元素大小 (n) :预计加入到布隆过滤器中的元素总数
(2)误判率 (p):将不存在的元素误判为存在的概率。在数据量大小一致的情况下,位数组长度越长误判率越小
(3)哈希函数个数 (k) :布隆过滤器使用的哈希函数数量,将输入数据映射到位数组的一个或多个位置上
(4)位数组大小 (m) :表示状态的二进制位的数量
-
k和m都可根据n和p计算得出,所以初始化布隆过滤器时只需要给出n和p的大小即可
-
布隆过滤器在线计算网址:https://krisives.github.io/bloom-calculator/

3. 布隆过滤器的原理
(1)建立一个二进制向量,并将所有位设置为0
(2)选定K个散列函数,用于对元素进行K次散列,计算向量的位下标
(3)添加元素:当需要添加一个元素到布隆过滤器中时,首先使用多个哈希函数对该元素进行哈希运算,得到多个哈希值。然后,将这些哈希值对应的位数组中的位置设置为1。
(4)查询元素(不存在一定不存在,存在不一定存在):同样使用多个哈希函数对该元素进行哈希运算,然后检查所有哈希值对应的位数组中的位置是否都为1。如果所有位置都为1,则认为该元素可能存在于集合中(注意是“可能”,因为存在误判的可能性);如果有任何一个位置为0,则确定该元素一定不存在于集合中。
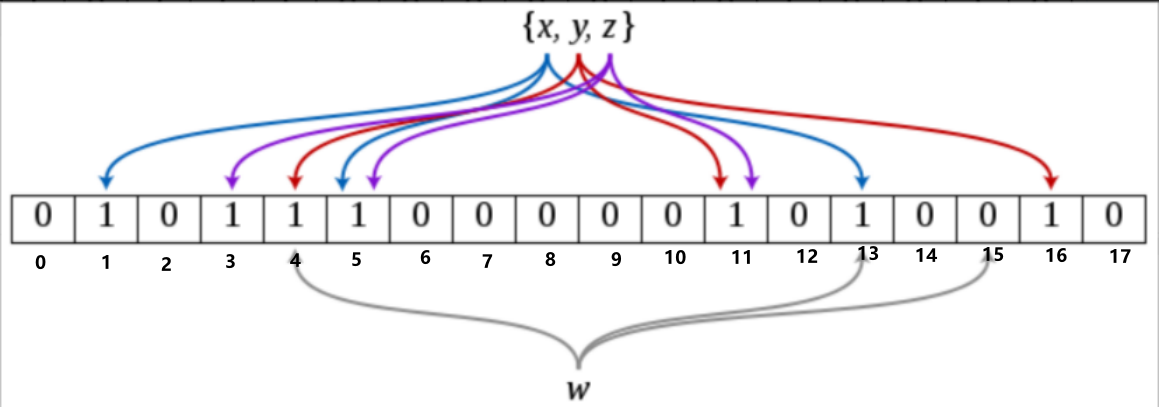
假设有元素x,y,z三个元素加入数组中,且哈希函数的个数为3。如上图所示,每个元素根据hash函数计算可得3个哈希值。现有一个w元素对应的哈希值分别为4、13和15,查询元素需要判断三个位置的值都为1。图中下标15的位置为0,所以该元素不存在。
如果再添加一个元素m,且m的哈希值其中有一个为15。这时4、13和15三个位置都为1,就会判断w元素存在,这种误判是由哈希冲突导致的。
如何解决布隆过滤器的误判?(不能完全解决,只能降低概率)
-
增加哈希函数的数量,降低哈希碰撞的概率
-
增大数组长度,也可以降低哈希碰撞的概率
4. 布隆过滤器的优缺点
-
优点:
-
占用空间小:相对于直接存储元素,布隆过滤器使用的空间要小得多。
-
查询速度快:布隆过滤器的查询操作通常只需要进行少量的位运算和哈希计算,因此速度非常快。
-
缺点:
-
存在一定的误判率:由于哈希冲突和位数组大小的限制,布隆过滤器无法保证查询结果的绝对准确性。
-
无法删除元素:布隆过滤器不支持删除操作,因为删除操作会影响其他元素的判断结果。布隆过滤器的使用场景布隆过滤器用于判断一个元素是否可能在一个集合中,可以用于很多场景。
5. 布隆过滤器的使用场景
布隆过滤器用于判断一个元素是否可能在一个集合中,可以用于很多场景。
-
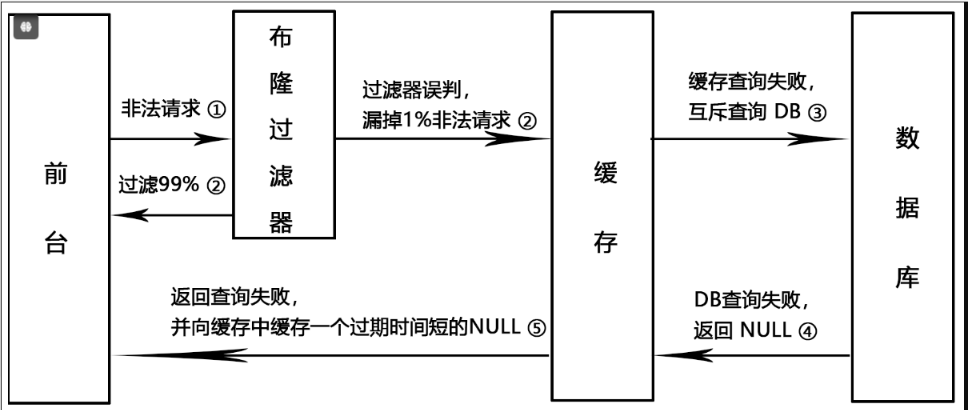
解决Redis缓存穿透问题
-
垃圾邮件过滤
-
用户请求限流,快速判断用户或IP地址的请求频率是否超过了限制
-
解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)SpringBoot中实现布隆过滤器
6. SpringBoot中实现布隆过滤器解决缓存穿透
(1)引入依赖
Redisson 是一个高性能的 Java 客户端库,用于开发基于 Redis 的分布式应用程序。
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.13.6</version></dependency>XML
(2)布隆过滤器配置
-
在application.properties中配置好redis的信息,将其注入到ReidsConfig类的属性中,根据属性配置redis的连接客服端
@Value("${spring.redis.host}")String host;@Value("${spring.redis.port}")String port;@Value("${spring.redis.password}")String password;
@Beanpublic RedissonClient redisson(){ Config config = new Config(); config.useSingleServer() .setAddress("redis://"+host+":"+port) .setPassword(password); return Redisson.create(config);}Java
(3)在商品业务中添加布隆过滤器
@Service
@Slf4j
public class ProductService {
@Autowired
ProductDao productDao;
@Resource
RedisTemplate<String,Product> redisTemplate;
@Autowired
RedissonClient redissonClient;
RBloomFilter<Integer> productFilter;
/**
* 初始化商品数据,将商品数据读入到redis的productFilter中
*/
@PostConstruct //项目启动时执行,也可以定时执行,比如每天执行一次
public void init(){
// 查询商品列表(只需要查询商品id列表,速度更快)
List<Product> productList = productDao.selectProductAll();
productFilter = redissonClient.getBloomFilter("productFilter");
// 初始化布隆过滤器,设置预计元素个数(结合每天的业务量设置)和误判率
productFilter.tryInit(productList.size() * 2L,0.01);
// 添加商品到布隆过滤器中
productList.forEach(product -> productFilter.add(product.getId()));
}
/**
* 根据id查询商品信息
*/
public Product getProductById(Integer id){
String productIdKey = "product."+id;
// 判断商品是否在布隆过滤器中存在
if(!productFilter.contains(id)){
throw new RuntimeException("布隆过滤器不存在该商品");
}
// 商品可能存在,在redis中查询商品信息
Product product = redisTemplate.opsForValue().get(productIdKey);
if(product!=null){
log.debug("在redis中查询到商品信息");
return product;
}
// redis中没有,在数据库中查询商品信息
product = productDao.selectProductById(id);
if(product==null){
// 在RBloomFilter工具类中没有找到移除元素的方法,所以这里直接抛出了异常
throw new RuntimeException("数据库中不存在该商品");
}
log.debug("在数据库中有,现存入redis中");
redisTemplate.opsForValue().set(productIdKey,product);
return product;
}
/**
* 添加商品,并添加到布隆过滤器中
*/
public Integer addProduct(Product product){
int affect = productDao.insertProduct(product);
productFilter.add(product.getId());
return affect;
}}Java
7. 思考
思考一: 如果商品id是有序的且从0开始,使用哪种方式记录表中的所有id比较好? 哪个空间更小?
(1)简单的位图,即商品id作为偏移量,将对应的位置设为1
(2)布隆过滤器,设置误判率为0.01
商品ID是从0开始的连续整数,那么使用位图是更好的选择。位图不仅空间效率更高,而且没有误报的问题。(如果不保证误判率,布隆过滤器空间效率更高)
注意: 使用简单位图的方式时,内存占用由最大的id决定,需要保证id不会大幅度跳动
思考二: 后续数据库中的数据量超过了设置的预添加元素数,布隆过滤器的数组会自动扩容吗?
不会。布隆过滤器一旦初始化,其位数组的大小和哈希函数的数量就是固定的。这意味着它不能自动扩容来适应更多的元素。如果尝试插入的元素数量超过了布隆过滤器的设计容量,误判率将会上升。